Springboot + ES8 + Deepseek-r1:32b 实现本地知识库(包含前后端源码) 发表于: 2025.03.05 | 分类于: 随笔 | 阅读次数: 463 ## 背景 公司想要做本地私有化的知识库,一年前OpenAI出来的时候用 Faiss加上 调用第三方的API(向量啥的) 做了一版了,后面裁员,这玩意就废弃了,又要重新搞。 ## 实现步骤 1、【上传文档】 → 【解析为文本】 → 【调用向量模型向量化】 → 【将向量数据存储到ES】 <br/> 2、【用户提问】 → 【把问题调用向量模型向量化】 → 【去ES里做向量检索】 → 【将查询的相似数据做语义相关度排序】 → 【把排序后的数据加上预制提示词调用 LLM 总结并返回】  ## 前提 首先在huggingface上下载模型 <br /> 模型下载地址:`https://huggingface.co/`  1、使用Ollama本地部署**deepseek-r1:32b** 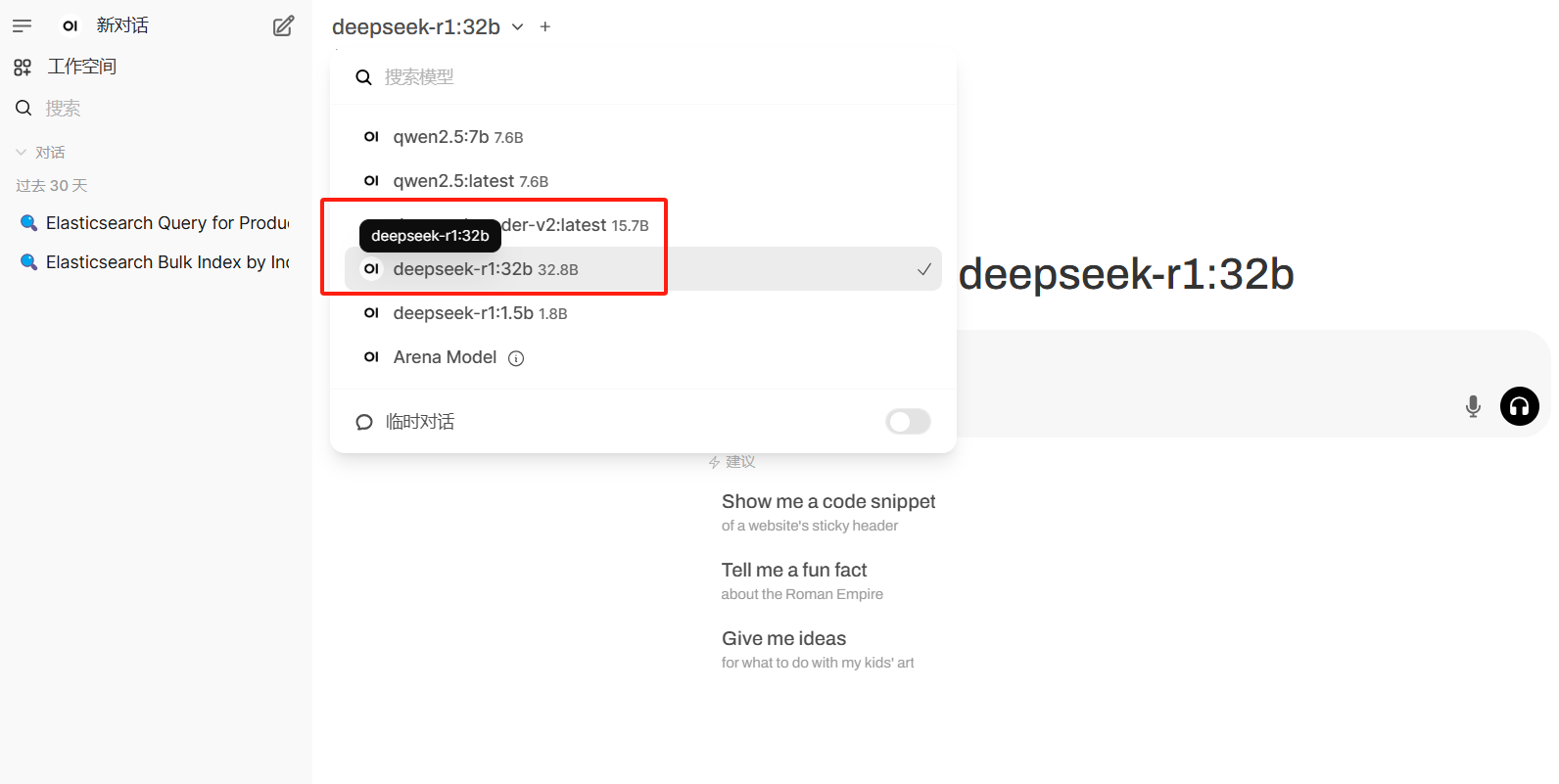 2、将 **m3e-large** 构建为 Api 服务 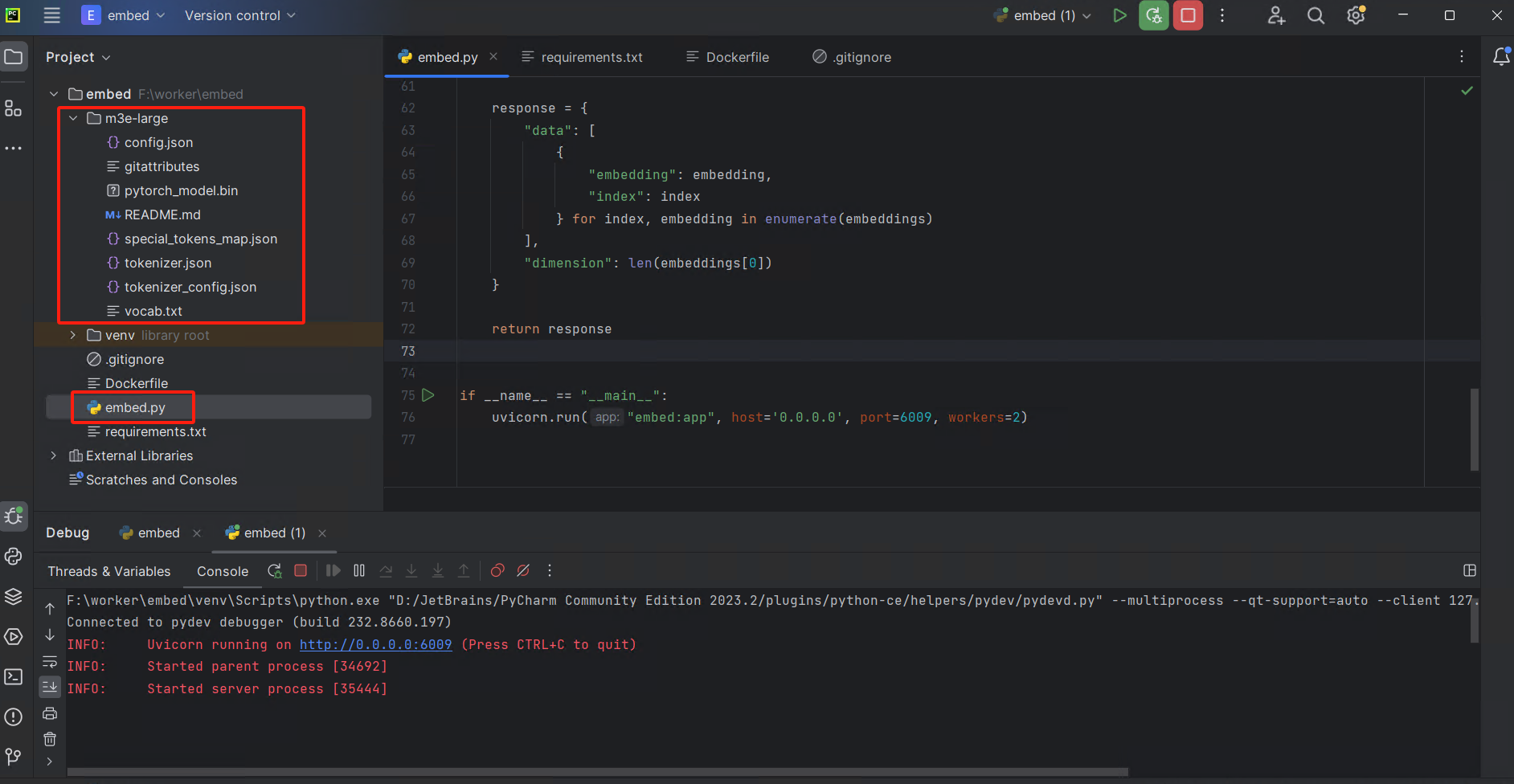 3、将 **bce-reranker-base_v1** 构建为 Api 服务  ## 演示效果 > **源码获取方式**,关注公众号,回复【知识库源码】代码包含 前端,springboot后端,python端   ## 步骤一:上传并解析文档 > 简单实现了一下pdf,word解析,用了OpenCV,OCR解析文档中的图片,图片解析效果一般  ``` public void uploadFile(MultipartFile file) { try { String projectPath = System.getProperty("user.dir"); Path tempDirPath = Paths.get(projectPath, TEMP_DIR); if (!Files.exists(tempDirPath)) { Files.createDirectories(tempDirPath); } // 获取文件名和扩展名 String originalFilename = file.getOriginalFilename(); String fileExtension = getFileExtension(originalFilename); // 生成临时文件路径 String timestamp = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMddHHmmss")); String tempFileName = timestamp + "_" + originalFilename; Path tempFilePath = Paths.get(projectPath, TEMP_DIR, tempFileName); // 保存上传的文件 file.transferTo(tempFilePath.toFile()); // 解析文件内容 Map<String, Object> parsedContent = parseFile(tempFilePath.toString(), fileExtension); // 保存到 Elasticsearch String text = parsedContent.get("text").toString(); KnowsIndex knowsIndex = new KnowsIndex(); knowsIndex.setId(String.valueOf(IdUtil.getSnowflakeNextId())); knowsIndex.setContent(text); knowsIndex.setContent_vec(EmbedClient.getEmbedding(embeddingUri, embeddingApiKey, text)); esDocumentService.indexSellList(Arrays.asList(knowsIndex)); // 清理临时文件 Files.deleteIfExists(tempFilePath); } catch (Exception e) { e.printStackTrace(); } } ``` ## 步骤二:调用 m3e-large 向量数据 ``` public static double[] getEmbedding(String uri, String apiKey, String inputText) throws IOException { OkHttpClient client = new OkHttpClient(); // 创建请求体 JSONObject requestBody = new JSONObject(); requestBody.put("input", Collections.singletonList(inputText)); // 创建请求 MediaType mediaType = MediaType.parse("application/json; charset=utf-8"); RequestBody body = RequestBody.Companion.create(requestBody.toJSONString(), mediaType); Request request = new Request.Builder() .url(uri) .addHeader("Authorization", "Bearer " + apiKey) .addHeader("Content-Type", "application/json") .post(body) .build(); // 发送请求 Response response = client.newCall(request).execute(); if (!response.isSuccessful()) { throw new IOException("Unexpected code " + response); } // 解析JSON响应 String responseBody = response.body().string(); EmbeddingResponse embeddingResponse = JSON.parseObject(responseBody, EmbeddingResponse.class); // 返回嵌入向量 return embeddingResponse.getData().get(0).getEmbedding(); } ``` ## 步骤三:保存到ES  ``` public void indexSellList(List<KnowsIndex> knowsIndexList) throws IOException { for (KnowsIndex knowsIndex : knowsIndexList) { knowsIndex.setContent_vec(EmbedClient.getEmbedding(embeddingUri, embeddingApiKey, knowsIndex.getContent())); IndexResponse response = client.index(i -> i .index(INDEX_NAME) .id(knowsIndex.getId()) .document(knowsIndex) ); log.info("Sell indexed: {}", response.id()); } } ``` ## 步骤四:用户搜索 > 用户搜索问题向量化后,去ES检索 ``` public List<SearchResult> searchVector(double[] queryVector) throws IOException { // 创建向量相似度查询 ScriptScoreQuery scriptScoreQuery = ScriptScoreQuery.of(q -> q .query(QueryBuilders.matchAll().build()._toQuery()) .script(Script.of(s -> s.inline(i -> i .source("double score = cosineSimilarity(params.query_vector, 'content_vec'); " + "score = Math.min(1.0, Math.max(0.0, score)); " + // 确保评分在[0, 1]之间 "if (score < params.threshold) { return 0; } else { return score; }") .params(Map.of( "query_vector", JsonData.of(queryVector), "threshold", JsonData.of(SIMILARITY_THRESHOLD) // 将阈值作为参数传递给脚本 )))))); // 创建bool查询,向量相似度查询作为should子句 Query boolQuery = QueryBuilders.bool(b -> b .should(scriptScoreQuery._toQuery()) ); Query functionScoreQuery = QueryBuilders.functionScore(fs -> fs .query(boolQuery) .scoreMode(FunctionScoreMode.Max) .boostMode(FunctionBoostMode.Replace) .minScore((double) SIMILARITY_THRESHOLD) ); // 执行合并后的查询 SearchResponse<KnowsIndex> combinedSearchResponse = client.search(s -> s .index(INDEX_NAME) .query(functionScoreQuery), KnowsIndex.class); // 处理查询的结果 return combinedSearchResponse.hits().hits().stream() .map(hit -> { double finalScore = Objects.nonNull(hit.score()) ? hit.score() : 0.0; return finalScore >= SIMILARITY_THRESHOLD ? new SearchResult(hit.source(), finalScore) : null; }) .filter(Objects::nonNull) .sorted(Comparator.comparingDouble(SearchResult::getScore).reversed()) .collect(Collectors.toList()); } ``` ## 步骤五:检索后的文档内容 调用deepseek总结 > 可以换成阿里千问或者是其他大语言模型 ``` public class OllamaClient { private static Map<String, Object> PARAMS = new HashMap<>(); private static Map<String, Object> OPTIONS = new HashMap<>(); static { OPTIONS.put("temperature", 0.3); // # 控制随机性(0-1,值越大越随机) OPTIONS.put("top_p", 0.5); // # 采样策略(0-1,值越小越集中) OPTIONS.put("max_tokens", 1024); // # 生成的最大 token 数 PARAMS.put("model", "deepseek-r1:32b"); PARAMS.put("stream", true); PARAMS.put("options", OPTIONS); } public static String PROMPT = "你是一个知识库,必须严格按照知识库检索的内容做最精简的回答,只回答关键信息,坚决杜绝胡编乱造,注意字数。" + "当所有知识库内容都与产品问题无关时,或者知识库检索到任何相关信息时,你的回答必须是“没有找到”这句话。" + " 以下是知识库:\n" + " { %content% }\n" + " 以上是知识库。 \n 以下是提问:"; public static void sendMsg(HttpServletResponse response, String uri, String query, String content) { try { // 设置SSE必要的响应头 response.setContentType("text/event-stream"); response.setCharacterEncoding("UTF-8"); response.setHeader("Cache-Control", "no-cache"); response.setHeader("Connection", "keep-alive"); URL url = new URL(uri); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setRequestMethod("POST"); conn.setRequestProperty("Accept", "text/event-stream"); conn.setRequestProperty("Content-Type", "application/json"); conn.setDoOutput(true); PARAMS.put("prompt", PROMPT.replace("%content%", content) + query); String json = JSON.toJSONString(PARAMS); try (OutputStream os = conn.getOutputStream()) { os.write(json.getBytes(StandardCharsets.UTF_8)); } int responseCode = conn.getResponseCode(); if (responseCode >= HttpURLConnection.HTTP_OK && responseCode < HttpURLConnection.HTTP_USE_PROXY) { try (BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(), StandardCharsets.UTF_8)); PrintWriter writer = response.getWriter()) { String line; while ((line = br.readLine()) != null) { if (!line.trim().isEmpty()) { // 构造SSE消息格式 writer.write("data: " + line + "\n\n"); writer.flush(); } } } } else { throw new RuntimeException("Failed : HTTP error code : " + responseCode); } } catch (Exception e) { try { response.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR); PrintWriter writer = response.getWriter(); writer.write("data: {\"error\": \"" + e.getMessage() + "\"}\n\n"); writer.flush(); } catch (IOException ioe) { e.printStackTrace(); } } } } ``` ## 前端代码 > 流式回复,Cursor生成,自己简单调了一下  ## END > 源码获取方式,关注公众号,回复【知识库源码】 代码包含前端,springboot后端,python端,不包含模型,模型太大了,自己去下载就行了。有不明白的可以加我微信联系我